
A ton of research has been done in Action Recognition in Videos (or Video Classification 🎞️) in the past.
In this article, I’ll talk about some of the milestone Convolution Neural Network (CovNet) based models in Video Classification.
Here we go !! 🚀
Single-frame based methods
Single Stream 2D-CNN

We have a video sequence having T number of frames of size H * W * 3 (where H is the Height, W is the Width, and 3 is the Depth). Every frame is processed separately. First, a kernel/filter of size K * K * 3 is applied to the image. The kernel first moves across image Width and then across image Height, and so on. This process outputs a feature map of H * W * 1 (assuming padding = same). We apply N number of such kernels to the image and thereby get N feature maps of size H * W * 1. We stack these feature maps to get H * W * N. Then, the flattening or pooling operation is used to convert this H * W * N array into a vector. Later, this vector is input to a Classifier which outputs class probabilities. This entire process is done for all the frames in the video sequence. Finally, we apply an arbitrator such as classwise-averaging to get the final result for the entire video.
Multi-frame based methods
Late Fusion 2D-CNN

We have a video sequence having T number of frames of size H * W * 3 (where H is the Height, W is the Width, and 3 is the Depth). Every frame is processed separately. First, a kernel/filter of size K * K * 3 is applied to the image. The kernel first moves across image Width and then across image Height, and so on. This process outputs a feature map of H * W * 1 (assuming padding = same). We apply N number of such kernels to the image and thereby get N feature maps of size H * W * 1. We stack these feature maps to get H * W * N. This entire process is done for all the frames in the video sequence. Then, all the H * W * N arrays are stacked together to form H * W * (T * N). Then, the flattening or pooling operation is used to convert this H * W * (T * N) array into a vector. Finally, this vector is input to a Classifier which outputs class probabilities.
Early Fusion 2D-CNN
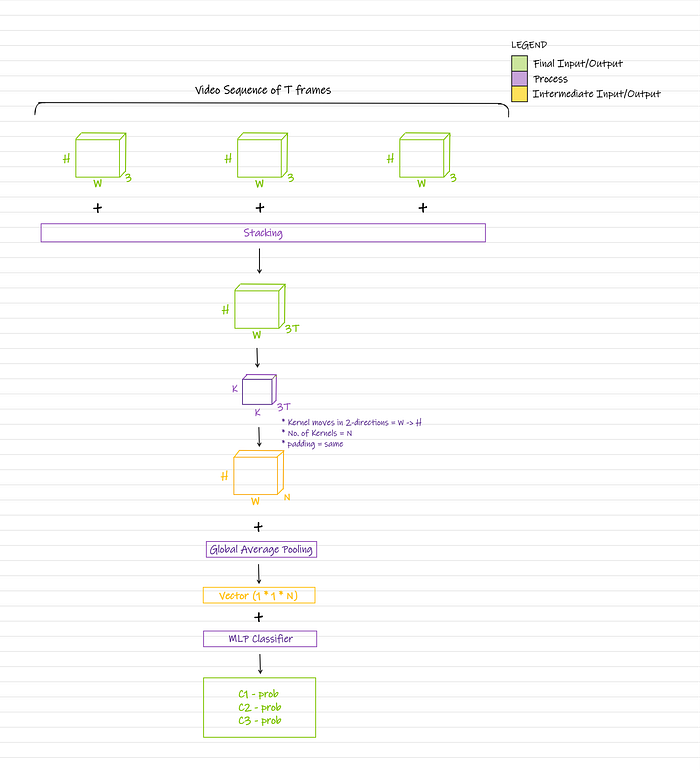
We have a video sequence having T number of frames of size H * W * 3 (where H is the Height, W is the Width, and 3 is the Depth). We stack these images to get H * W * (3 * T). Then, a kernel/filter of size K * K * (3 * T) is applied to the stack. The kernel first moves across stack Width and then across stack Height, and so on. This process outputs a feature map of H * W * 1 (assuming padding = same). We apply N number of such kernels to the stack and thereby get N feature maps of size H * W * 1. We stack these feature maps to get H * W * N. Then, the flattening or pooling operation is used to convert this H * W * N array into a vector. This vector is input to a Classifier which outputs class probabilities.
3D-CNN
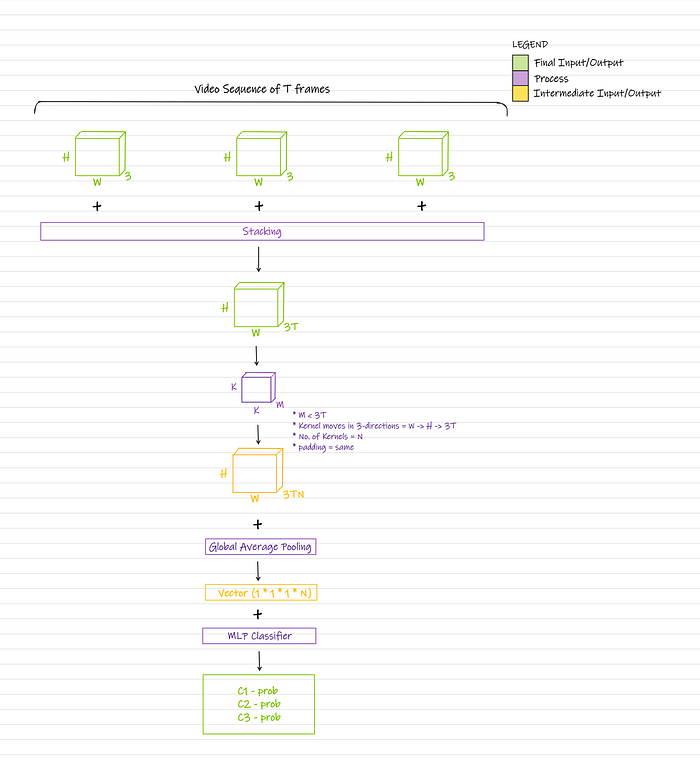
We have a video sequence having T number of frames of size H * W * 3 (where H is the Height, W is the Width, and 3 is the Depth). We stack these images to get H * W * (3 * T). Then, a kernel/filter of size K * K * M (where M < 3 * T) is applied to the stack. The kernel first moves across stack Width, then across stack Height, and then across stack Depth, and so on. This process outputs a feature map of H * W * (3 * T) (assuming padding = same). We apply N number of such kernels to the stack and thereby get N feature maps of size H * W * (3 * T). We stack these feature maps to get H * W * (3 * T * N). Then, the flattening or pooling operation is used to convert this H * W * (3 * T * N) array into a vector. This vector is input to a Classifier which outputs class probabilities.
Many milestone models such as C3D, I3D, and P3D are based on 3D-CNN.
Observations
At first glance, Early Fusion 2D-CNN and 3D-CNN look quite similar. The main difference lies in the convolution stage.
Early Fusion 2D-CNN convolution stage
- No. of trainable parameters = (K * K * 3 * T + 1) * N
- Output size = H * W * N
3D-CNN convolution stage
- No. of trainable parameters = (K * K * M + 1) * N
- Output size = H * W * 3 * T * N
Early Fusion 2D-CNN has a higher number of trainable parameters than 3D-CNN but a smaller output size.
Choose wisely!!💡🦉
References
- Single-frame/Early-fusion/Late-fusion 2D-CNN: https://cs.stanford.edu/people/karpathy/deepvideo/deepvideo_cvpr2014.pdf
2. 3D-CNN: https://arxiv.org/pdf/1711.11248v3.pdf

That will be it for this article.
Don’t forget to 👏 if you liked the article.
If you have any questions or would like something clarified, you can find me on LinkedIn.
~happy learning.